3-1 人工神经网络(上)
如果说训练模型就像制造一个工艺品,数据是制作材料,模型是制作技艺。那么五花八门的模型,就好像不同的工匠,每个人都有自己专精的领域。
比如,有人善于制造金银器物,有人善于制造翡翠宝石,就好像有些模型适合分析图像,有些模型适合处理文本。又如,有人精于制作小巧首饰,有人长于打造大型雕塑,就好像有些模型短小精干,有些模型庞大复杂。再如,有人喜欢照着模子制作,有人喜欢随心所欲创造。就好像有些模型适合有监督任务,有些模型适合无监督任务。
模型选择的目的,就是要让合适的人,干合适的事儿,正所谓人尽其才,物尽其用,避免浪费。
本期课程我们就来聊一聊深度学习的各类模型。这部分,我们将用较大的篇幅来分别讲解ANN、CNN、RNN、Transformer、GAN、GCN网络模型的结构、特点,以及适用场景。我们先来说一说人工神经网络模型(ANN)。
在此之前,首先要搞明白一个问题,什么是模型?
百度百科说模型是通过主观意识借助实体或者虚拟表现,构成客观阐述形态结构的一种表达目的的物件。翻译成好理解的语言,就是一种对事物规律的抽象概括。还不明白的话,我们看个例子。
比如你去超市买苹果,看到标价写着苹果2元钱一斤,那么在你的心中就建立了 苹果的花费 = 2 × 重量 这一模型。没错,这就是模型,其中苹果重量是自变量,花费是因变量, 花费会随着重量的改变而改变。苹果的价格2元,就叫模型参数或者权重。
当你第二天去别的超市,又买了两斤苹果,结果花了5元钱时,你就会用心中的模型进行评估, 苹果的花费应该是 2 × 2 = 4元。此时多花的1元钱,就会对你产生影响,让你不自觉的调整心中的模型,觉得苹果的花费应该等于 某个大于2元的数 × 重量,也就是苹果的价格从2元变成了2+。
没错,这就是模型的学习。
那这个大于2元的数,到底应该多多少?这个因人而异,有的人比较敏感,会觉得至少要2.4元,也有的人能比较迟钝,会觉得2.1元就差不多了。那么这个多出来的0.4 或者 0.1 就是传说中的学习率。
那么假设你心中的模型调整为了苹果的花费 = 2.1 × 重量,结果第三天,你买2斤苹果花了3元,那么模型会怎么学习呢?这个问题留给大家思考。
这就是神经网络。
你可能会质疑,这么一个小学生都会的方程哪有半点“网络”的感觉?实际上,刚刚的这个例子中,苹果花费C = 苹果价格P × 重量 W 是一个线性方程,这个模型也被称为线性回归,这正是神经网络最原始的形态。
接下来我们说说什么是神经网络。神经网络是一种以线性回归为基础进行分布式并行计算的模型。我们来看一个最简单的网络结构。
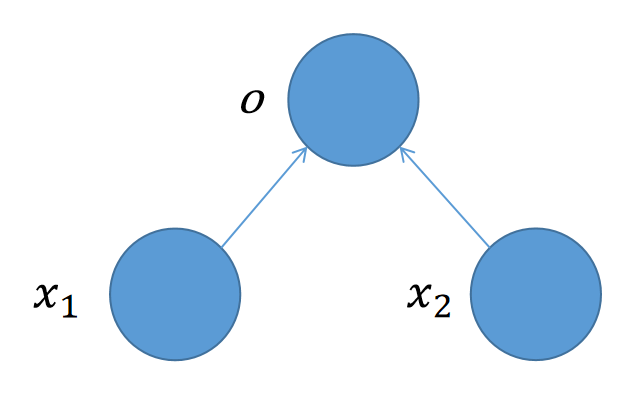
其中\(x_1\)和\(x_2\)为输入,这一层也叫作输入层,o为输出,这一层也叫作输出层。这张图描绘了一个输入个数为2,输出个数为1的神经网络。两条连线,则表明了输出层的输出结果o是由\(x_1\)和\(x_2\)共同决定的。输出层神经元和所有输入都相连,像这样的输出层,也被称为全连接层。
这样的网络,写成公式就是:
我们可以将\(x_1\)、\(x_2\)理解为影响输出o的不同的特征。在买苹果的例子中,总花费就是o,\(x_1\)可以是苹果的重量, \(x_2\)可以是苹果的品种。由于线性回归未必会是一个过原点的直线,因此要增加一个偏置项b。
这就是神经网络最简单的形态,接下来用代码来实现。简单起见,我们还是假设苹果花费只和重量有关,首先需要自动生成一个数据集:
def generate_data(num):
xs = np.random.rand(num)
xs = np.sort(xs)
ys = np.zeros(num)
for i in range(num):
x = xs[i]
ys[i] = 2*x+(0.5-np.random.rand())/5+0.5
return xs,ys
这里引入了一个随机数让样本围绕\(y=2x + 0.5\)波动,生成的数据就像这样:
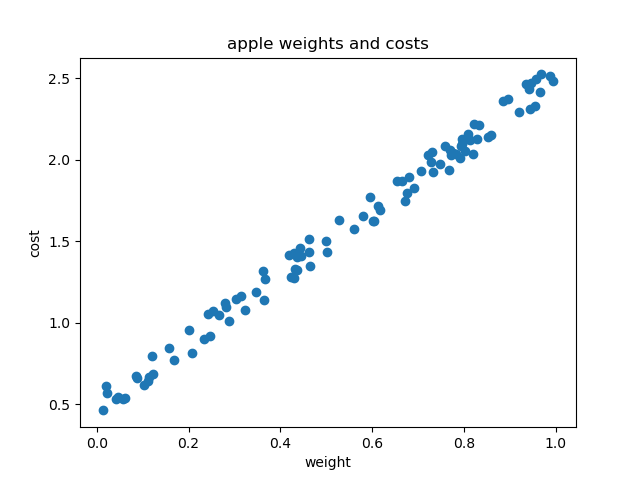
现在我们尝试建立一个模型,去学习这些数据。既然是线性回归,那么首先需要建立一个预测函数,并初始化w和b的值。
y_pre = w * xs + b
w = 1
b = 1
接下来需要定义代价函数了。代价函数也叫损失函数,是一种用来衡量预测结果和真实值差异的函数。最简单的形式是直接求差的绝对值 \(loss = |真实结果 - 预测结果|\),稍微复杂一点则是求均方误差MSE或者交叉熵Cross Entropy,不同的损失函数适合的任务不同,MSE更适合回归预测,交叉熵则在分类任务中效果更好。详细内容,我们会在代价函数专题部分进行讲解。
这里我们需要预测苹果的价格,属于回归任务,因此选择MSE效果更好,那么定义损失函数如下:
e = (ys[i] - y_pre) ** 2
量化误差是为了依据误差调整模型参数,让预测结果向着真实值靠近。优化方法采用梯度下降法,这里只展示代码,相关内容后面再做介绍。
dw = 2 * x ** 2 * w + 2 * x * b - 2 * x * y
db = 2 * b + 2 * x * w - 2 * y
alpha = 0.1
w = w - alpha * dw
b = b - alpha * db
至此,神经网络训练的全部代码已经给出:
import matplotlib.pyplot as plt
import numpy as np
xs = np.random.rand(100)
xs = np.sort(xs)
ys = np.array([(2*x+(0.5-np.random.rand())/5+0.5) for x in xs])
w=1
b=1
z = w*xs+b
for step in range(500):
for i in range(100):
x = xs[i]
y = ys[i]
dw = 2 * x ** 2 * w + 2 * x * b - 2 * x * y
db = 2 * b + 2 * x * w - 2 * y
alpha = 0.1
w = w - alpha * dw
b = b - alpha * db
plt.clf()
plt.scatter(xs,ys)
z = w*xs + b
plt.plot(xs, z)
plt.title("apple")
plt.xlabel('weight')
plt.pause(0.1)
运行一下,可以看到预测直线随着迭代次数的增加,从
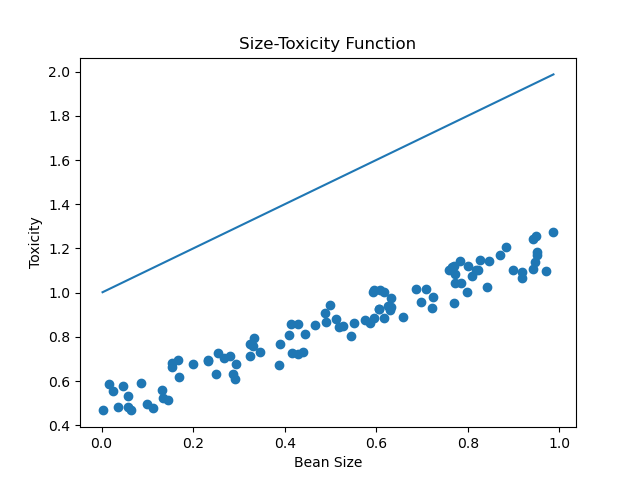
逐渐逼近
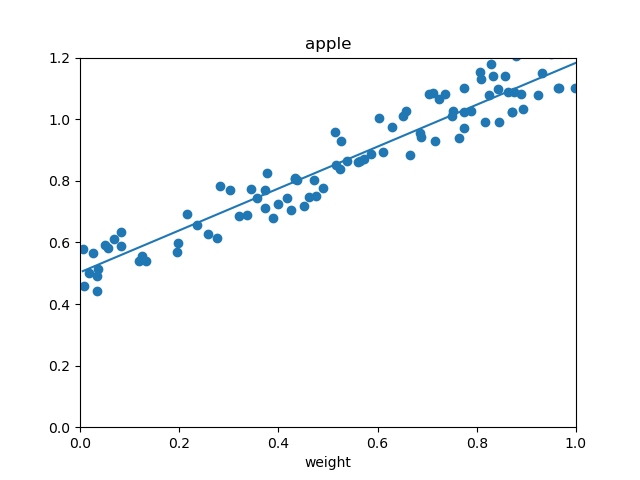
预测函数也越发接近\(y=2x + 0.5\)。最终迭代500轮以后,\(w=1.93,b=0.53\)。
每一个人,在认知现实世界时,很少会精确判断出准确的数值,比如人的身高,距离的远近,食物的口味等等。人们更多的时候会通过定性,而非定量的方法用高矮、远近、好不好吃来描述客观事物。也就是打标签。
当输出结果从一个数值变成一个类别以后,我们的模型也要进行相应的调整。比如同样是判断苹果的花费,如果我们用高和低来进行描述,那么就需要对模型进行相应的调整。
首先,生成数据的时候,ys不再是一个精确的数值,而需要变成0或者1,代表花费的高低。
xs = np.random.rand(100)
xs = np.sort(xs)
ys = np.zeros(100)
for i in range(100):
x = xs[i]
yi = 2*x+(0.5-np.random.rand())/50+0.5
if yi > 1.4:
ys[i] = 1
另外,需要增加一个分类函数,将神经网络的输出映射到0和1之间,这里我们采用sigmoid函数。
a = 1 / (1 + np.exp(-z))
完整代码如下:
import matplotlib.pyplot as plt
import numpy as np
xs = np.random.rand(100)
xs = np.sort(xs)
ys = np.zeros(100)
for i in range(100):
x = xs[i]
yi = 2 * x + (0.5 - np.random.rand()) / 50 + 0.5
if yi > 1.4:
ys[i] = 1
#预测函数
w = 1
b = 1
z = w * xs+b
a = 1/(1+np.exp(-z))
for step in range(5000):
for i in range(100):
x = xs[i]
y = ys[i]
z = w * x+b
a = 1 / (1 + np.exp(-z))
e = (y - a) ** 2
de_a = -2 * (y-a)
da_z = a * (1-a)
dz_w = x
de_w = de_a * da_z * dz_w
dz_b = 1
de_b = de_a * da_z * dz_b
alpha = 0.05
w = w - alpha * de_w
b = b - alpha * de_b
if step % 100 == 0:
plt.clf()
plt.scatter(xs,ys)
z = w*xs + b
a = 1/(1+np.exp(-z))
plt.xlim(0, 1)
plt.ylim(0, 1.2)
plt.plot(xs, a)
plt.title("apple", fontsize=12)
plt.xlabel('weight')
plt.pause(0.1)
可以看到,最终我们的样本被很好地分为了两类。
训练前:
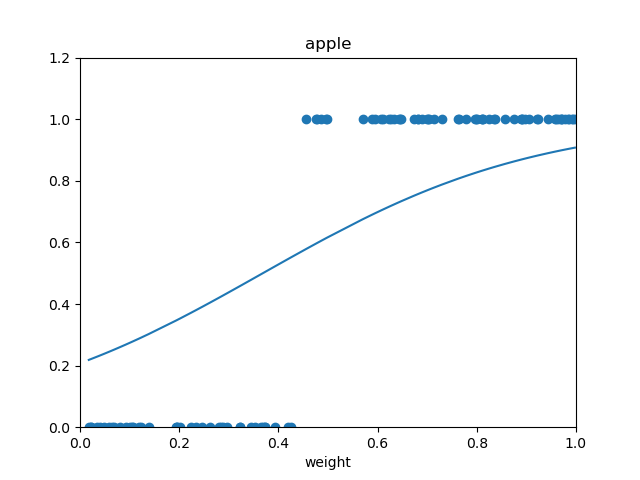
训练后:
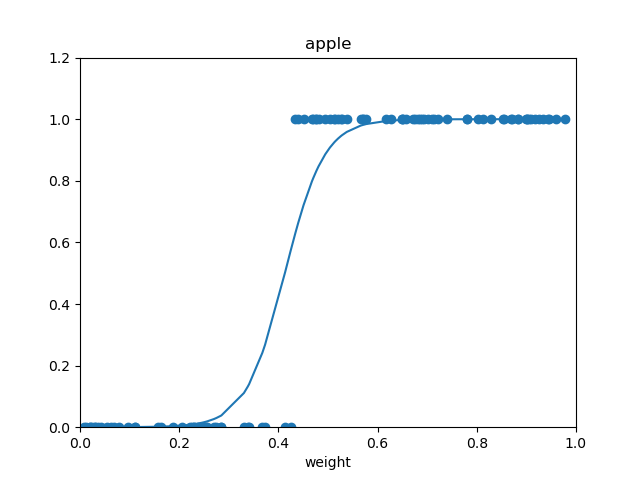
单层的神经网络可以很好的解决线性可分的问题,就是可以找到一条线,将两类样本分开。
但后来,图灵奖获得者Marvin Minsky发现,单层神经网络无法解决“异或”问题,直接导致了神经网络长达10多年的沉寂。
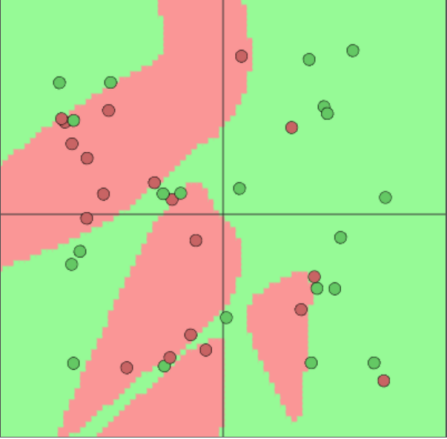
然而祸兮福所倚,福兮祸所伏,随着“异或”问题的提出,深度神经网络应运而生了。它在单层神经网络的基础上引入了若干个隐藏层,置于输入层和输出层之间。深度神经网络成功的解决了“异或”问题,这部分在扩展阅读里面会详细介绍。
正是深度网络的出现,打开了深度学习的大门,让神经网络一跃成为机器学习的宠儿,它是如何做到的,我们下期再讲。
扩展阅读
那什么是“异或”问题呢?
“异或”和“与”、“或”运算一样,是一种逻辑运算符。简单来说就是假设我们有\(x_1\)、\(x_2\)两种输入,\(x_1\)、\(x_2\)的值不是0就是1,那么“与”操作是只有当\(x_1\)、\(x_2\)同时为1是,才输出1,否则输出0;“或”操作是只要\(x_1\)、\(x_2\)两者有一个为1,则输出1,否则输出0;“异或”则是,\(x_1\)、\(x_2\)同时为0或同时为1时,输出0,否则输出1。
画出来就像这样,对于最后一张图,我们没法用一条直线将0,1分割开,这类问题也被统称为线性不可分问题。
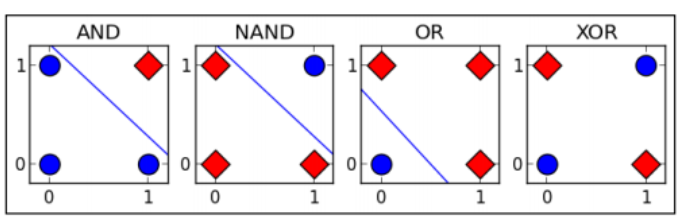
这个问题真的无解吗?
在当时可能确实如此,然而随着计算机硬件的升级,“异或”问题迎刃而解。
怎么解决的?
团结就是力量,增加神经元的个数,当然不是横向扩展,而是纵向延申。我们可以增加网络的深度。在输入层和输出层之间,增加的这一层叫做隐藏层,网络结构大致是这样。
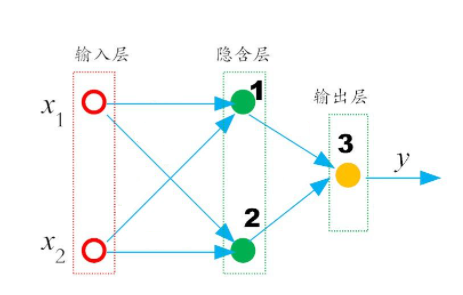
左侧的输入层就是模型的输入\(x_1\)、\(x_2\),中间新增加的叫隐含层,它的层数可以根据问题复杂程度自由扩展,当层数n=0时,模型就退化成了单层神经网络,当层数n>0时,模型被称为深度神经网络。每一层的神经元个数需要人工设定,这里暂定为2。右侧的输出层输出0或1,输出层的神经元个数取决于要解决的问题,当输出是一个数字时,只要一个神经元就够了,当输出是多分类任务时,神经元的个数要和分类类别数相同。
这里我们直接公布一个解决异或问题的正确答案。
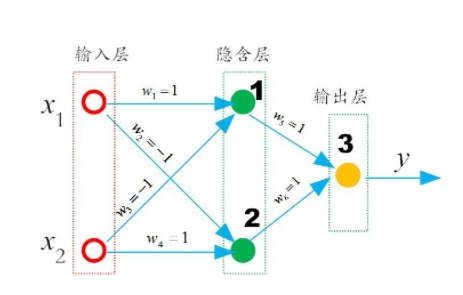
这个网络的权重已经写好了,神经元节点的偏置项b则统一取0.5,激活函数取阶跃函数sgn,
我们一起验证一下:
当\(x_1\),\(x_2\)同时为1时,
然后最终的输出层
当\(x_1\),\(x_2\)同时为0时,
然后最终的输出层
没问题,\(x_1\),\(x_2\)相同时,输出为0。
当\(x_1\),\(x_2\)不相同时,比如\(x_1=1\),\(x_2=0\),
然后最终的输出层
\(x_1\),\(x_2\)的值互换也是一样,
当\(x_1=0\),\(x_2=1\),
然后最终的输出层
可以看到,\(x_1\),\(x_2\)不同时,输出为1。如此,我们用一个实例证明了多层感知机能够解决“异或”问题。在这里,网络中的权值和阈值是我们事先给定的,而实际上,它们是需要神经网络自己通过反复地“试错”学习而来,而且能够完成“异或”功能的网络权重也不是唯一的。有兴趣的同学可以自己实验一下。